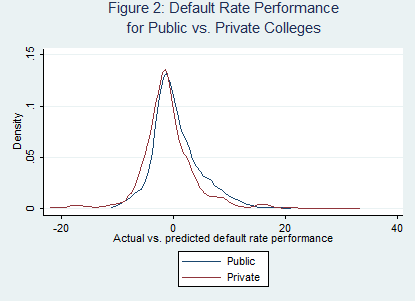
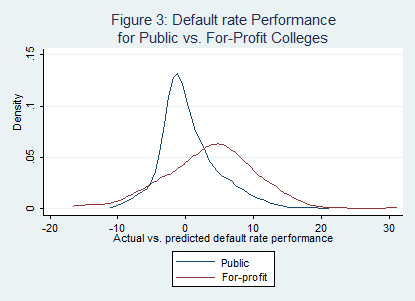
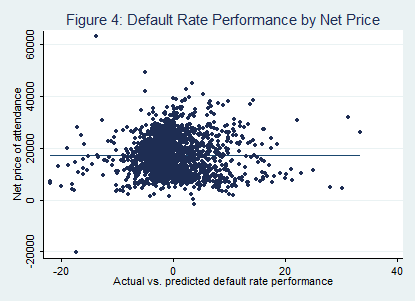
It is no surprise to those in the higher education world that student characteristics and institutional resources are strongly associated with student outcomes. Colleges which attract academically elite students and have the ability to spend large sums of money on instruction and student support should be able to graduate more of their students than open-access, financially-strapped universities, even after holding factors such as teaching quality constant. But an article in today’s Inside Higher Ed shows that there is a great deal of interest in determining the correlation between inputs and outputs (such as graduation).
The article highlights two new studies that examine the relationship between inputs and outputs. The first, by the Department of Education’s Advisory Committee on Student Financial Assistance, breaks down graduation rates by the percentage of students who are Pell Grant recipients, per-student endowments, and ACT/SAT scores using IPEDS data. The second new study, by the president of Colorado Technical University, finds that four student characteristics (race, EFC, transfer credits, and full-time status) explain 74% of the variation in an unidentified for-profit college’s graduation rate. His conclusion is that “public [emphasis original] policy will not increase college graduates by focusing on institution characteristics.”
While these studies take different approaches (one using institutional-level data and the other using student-level data), they highlight the importance that student and institutional characteristics currently have in predicting student success rates. These studies are not novel or unique—they follow a series of papers in HCM Strategists’ Context for Success project in 2012 and even more work before that. I contributed a paper to the project (with Doug Harris at Tulane University) examining input-adjusted graduation rates using IPEDS data. We found R-squared values of approximately 0.74 using a range of student and institutional characteristics, although the predictive power varied by Carnegie classification. It is also worth noting that the ACSFA report calculated predicted graduation rates with an R-squared value of 0.80, but they control for factors (like expenditures and endowment) that are at least somewhat within an institution’s control and don’t allow for a look at cost-effectiveness.
This suggests the importance of taking a value-added approach in performance measurement. Just like K-12 education is moving beyond rewarding schools for meeting raw benchmarks and adopting a gain score approach, higher education needs to do the same. Higher education also needs to look at cost-adjusted models to examine cost-effectiveness, something which we do in the HCM paper and I have done in the Washington Monthly college rankings (a new set of which will be out later this month).
However, even if a regression model explains 74% of the variation in graduation rates, a substantial amount can be attributed either to omitted variables (such as motivation) or institutional actions. The article by the Colorado Technical University president takes exactly the wrong approach, saying that “student graduation may have little to do with institutional factors.” If his statement is accurate, we would expect colleges’ predicted graduation rates to be equal to their actual graduation rates. But, as anyone who was spent time on college campuses should know, institutional practices and policies can play an important role in retention and graduation. The 2012 Washington Monthly rankings included a predicted vs. actual graduation rate component. While Colorado Tech basically hit its predicted graduation rate of 25% (with an actual graduation rate one percentage point higher), other colleges outperformed their prediction given student and institutional characteristics. For example, San Diego State University and Rutgers University-Newark, among others, outperformed their prediction by more than ten percentage points.
While incoming student characteristics do affect graduation rates (and I’m baffled by the amount of attention on this known fact), colleges’ actions do matter. Let’s highlight the colleges which appear to be doing a good job with their inputs (and at a reasonable price to students and taxpayers) and see what we can learn from them.